This is the third installment of the Human-vs-Bot project. We began by simulating response behavior and generating timestamped data using distinct time
distributions to reflect plausible differences between human and bot activity. In part two, we used logistic regression to explore how separable the two
groups were. Here, we extend our modeling by applying Support Vector Machines and Random Forests to the same task.
Machine Learning
Although logistic regression is a machine learning method, it’s often introduced in the context of traditional statistics, leading many to overlook its role in classification tasks.
In this section, we explore two additional supervised learning approaches: Support Vector Machines and Random Forests.
Support Vector Machines (SVM)
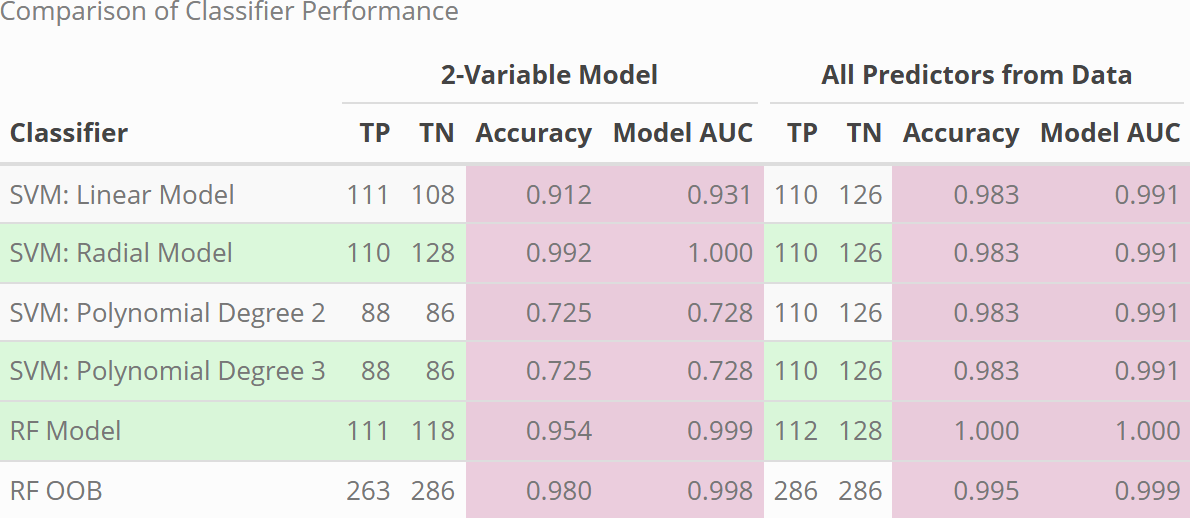
SVMs calculate the maximal-margin hyperplane that best separates classes in feature space. By choosing a non-linear kernel (e.g. radial or polynomial), they can learn complex decision boundaries.
Although SVMs are inherently binary classifiers, they can be extended to multiclass problems via schemes like one-vs-rest (OvR) or one-vs-one (OvO), where multiple SVM models are trained
and their outputs combined either by selecting the highest decision-function score or by majority vote. In this project, we compared SVM performance (using linear, radial, and polynomial
kernels) to logistic regression, evaluating accuracy.
Random Forests (RF)
Random forests are ensembles of decision trees that reduce overfitting by averaging predictions across many trees, each trained on a bootstrap sample and a random subset of features.
This approach naturally captures nonlinear relationships and variable interactions. Because random forests use bagging, you can also estimate performance directly on the training set
via out-of-bag (OOB) samples.
Compared to SVMs, Random Forests are less sensitive to feature scaling and multicollinearity. We evaluated RF models using both a reduced set of predictors and an expanded set.
While feature selection was used here for illustration, Random Forests are often robust enough to handle a larger number of inputs without strict preprocessing.
Figure: Classifier performance by accuracy and AUC across models using both reduced and full feature sets.